机器学习中分类性能的评价指标总结
在机器学习任务中,对于分类问题,有着很多的不同的评价指标,不同的指标可以适用于不同的任务。
这里对这些不同的评价指标进行简单总结。
假设对于一个分类问题,我们关注的类别称为正样本,其他类别都是负样本,则有混淆矩阵如下:
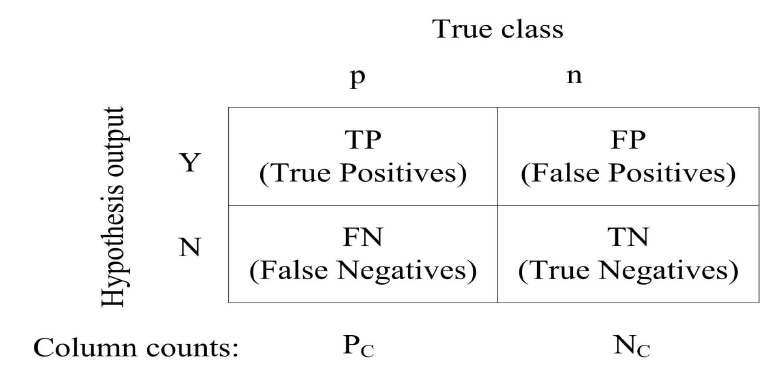
-
Accuracy : 准确率
准确率表示样本被正确分类的比例,即: Accuracy = (TP + TN) / (FP + FN)
-
Precision : 精度
精度表示的是所有被分为正的样本中,真正是正样本的比例,即: P = TP / (TP + FP)
-
Recall : 召回率/查全率
召回率表示的是,所有的正样本被正确分类的比例,即: R = TP / (TP + FN)
-
F1值
F1值是精度和召回率的调和平均,即: 2/F1 = 1/P + 1/R
所以,F1 = 2P·R/(P+R)
-
ROC曲线 称为”受试者工作特征曲线 “ ROC使用两个字表,TP_rate(Recall)、FP_rate TP_rate = TP / (TP + FN) : 表示正样本被正确分类的比例,其实就是recall FP_rate = FP / (FP + TN) : 表示负样本分为正样本的比例
在ROC 空间中,每个点的横坐标是FP_rate,纵坐标是TP_rate,这也就描绘了分类器在TP(真正的正例)和FP(错误的正例)间的trade-off。ROC的主要分析工具是一个画在ROC空间的曲线——ROC curve。我们知道,对于二值分类问题,实例的值往往是连续值,我们通过设定一个阈值,将实例分类到正类或者负类(比如大于阈值划分为正类)。因此我们 可以变化阈值,根据不同的阈值进行分类,根据分类结果计算得到ROC空间中相应的点,连接这些点就形成ROC curve。ROC curve经过(0,0)(1,1),实际上(0, 0)和(1, 1)连线形成的ROC curve实际上代表的是一个随机分类器。一般情况下,这个曲线都应该处于(0, 0)和(1, 1)连线的上方。如图所示。
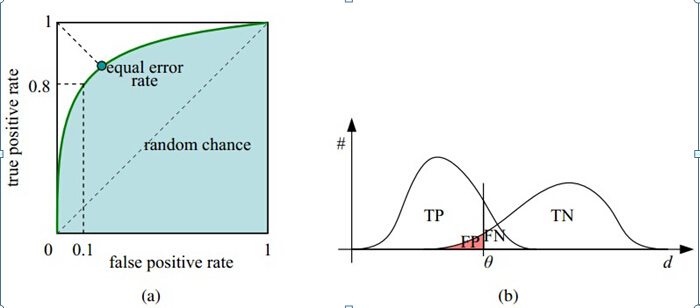
-
AUC
ROC曲线下面围成的面积。
一般来说,如果ROC是光滑的,那么基本可以判断没有太大的overfitting(比如图中0.2到0.4可能就有问题,但是样本太少了),这个时候调模型可以只看AUC,面积越大一般认为模型越好。